


Автори зображення: Google
Не відставати від такої індустрії, що швидко розвивається, як штучний інтелект, є важким завданням. Отже, щоб штучний інтелект міг зробити це за вас, ось корисний огляд історій минулого тижня у світі машинного навчання разом із відомими дослідженнями та експериментами, про які ми б не розповідали окремо.
Цього тижня компанія Google домінувала в циклі новин про штучний інтелект, представивши декілька нових продуктів на своїй щорічній конференції розробників вводу-виводу. Вони охоплюють широкий діапазон від штучного інтелекту для створення коду, який має конкурувати з Copilot від GitHub, до музичного генератора штучного інтелекту, який Turns текстові підказки в короткі пісні.
Досить багато з цих інструментів, здається, законно економлять робочу силу — тобто більше маркетингового пуху. Мене особливо заінтригував Project Tailwind, програма для створення нотаток, яка використовує штучний інтелект для організації, узагальнення й аналізу файлів із моєї особистої папки Google Docs. Але вони також розкривають обмеження та недоліки навіть найкращих сучасних технологій ШІ.
Візьмемо, наприклад, PaLM 2, останню велику мовну модель (LLM) Google. PaLM 2 буде працювати над оновленим інструментом чату Google Bard, конкурентом компанії ChatGPT від OpenAI, і служити базовою моделлю для більшості нових функцій ШІ від Google. Але в той час як PaLM 2 може писати код, повідомлення електронної пошти тощо, як і аналогічні LLM, він також відповідає на запитання токсичним і упередженим способом.
Генератор музики Google також дещо обмежений у своїх можливостях. Як я написав власноруч, більшість пісень, створених мною за допомогою MusicLM, у кращому випадку звучать прийнятно, а в гіршому – як випущена чотирирічна дитина DAW.
Багато написано про те, як штучний інтелект замінить робочі місця — потенційно еквівалентно 300 мільйонам штатних робочих місць, згідно з звіт від Goldman Sachs. в розвідка За словами Харріса, 40% працівників, знайомих із чат-ботом OpenAI на основі ШІ, ChatGPT, хвилюються, що він повністю замінить їм роботу.
ШІ Google — це ще не все. Власне, компанія Можна сказати, що позаду в гонці за штучний інтелект. Але незаперечним фактом є те, що Google наймає працівників Деякі з найкращих дослідників ШІ у світі. І якщо це найкраще, з чим вони можуть керувати, це свідчить про те, що штучний інтелект далекий від вирішення проблеми.
Ось інші заголовки AI, помічені за останні кілька днів:
- Meta привносить генеративний ШІ в оголошення: Цього тижня Meta анонсувала своєрідну пісочницю штучного інтелекту для рекламодавців, яка допоможе їм створювати альтернативні копії, створювати фон за допомогою текстових підказок і обрізати зображення для оголошень у Facebook або Instagram. Компанія повідомила, що наразі ці функції доступні для вибраних рекламодавців і розширять охоплення для більшої кількості рекламодавців у липні.
- Доданий контекст: Anthropic розширив контекстне вікно для Claude — своєї флагманської генерації тексту та моделі AI, яка все ще знаходиться на стадії попереднього перегляду — з 9000 токенів до 100 000 токенів. Контекстне вікно вказує, який текст розглядає форма перед створенням додаткового тексту, тоді як лексеми представляють необроблений текст (наприклад, «круто» буде розділено на лексеми «фан», «тас» і «тик»). Історично і навіть сьогодні погана пам’ять була перешкодою для корисності генерації тексту для ШІ. Але більші контекстні вікна можуть це змінити.
- Антропія сприяє «конституційному штучному інтелекту»: Більші контекстні вікна не є єдиним фактором, що відрізняє антропні моделі. Цього тижня компанія детально розповіла про «конституційний штучний інтелект» — свій внутрішній підхід до навчання штучному інтелекту, який має на меті наповнити «цінності» систем ШІ «конституцією». На відміну від інших підходів, Anthropic стверджує, що конституційний ШІ робить поведінку систем легшою для розуміння та легшою для модифікації за потреби.
- LLM призначений для дослідження: Некомерційна організація Allen Institute for Artificial Intelligence Research (AI2) оголосила, що планує навчання LLM, орієнтоване на дослідження, під назвою Open Language Model, додавши до великої та зростаючої бібліотеки з відкритим кодом. AI2 розглядає модель відкритої мови, або скорочено OLMo, як платформу, а не просто модель, яка дозволить дослідницькому співтовариству взяти кожен компонент, створений AI2, і або використовувати його самостійно, або прагнути вдосконалити його.
- Новий фонд ШІ: Інші новини AI2: AI2 Incubator, некомерційний фонд стартапів у галузі штучного інтелекту, повернувся втричі більше ніж попередній розмір — 30 мільйонів доларів проти 10 мільйонів доларів. Двадцять одна компанія пройшла через інкубатор з 2017 року, залучивши близько 160 мільйонів доларів подальших інвестицій і щонайменше одне велике придбання: XNOR, прискорювач штучного інтелекту та ефективний пристрій, який пізніше придбала Apple приблизно за 200 мільйонів доларів.
- Правила впровадження генеративного ШІ ЄС: Під час серії голосувань у Європейському парламенті цього тижня депутати Європарламенту підтримали низку поправок до законопроекту блоку про штучний інтелект, включаючи врегулювання вимог до так званих фундаментальних моделей, які лежать в основі генеративних технологій штучного інтелекту, таких як ChatGPT OpenAI. Поправки поклали на постачальників базових моделей обов’язок запровадити перевірки безпеки, заходи щодо керування даними та зменшити ризики перед виведенням своїх моделей на ринок.
- Універсальний перекладач: Google тестує нову потужну службу перекладу, яка відтворює відео новою мовою, а також синхронізує слова мовця зі словами, які вони ніколи не вимовляли. Це може бути дуже корисним з багатьох причин, але компанія заздалегідь повідомила про потенційні зловживання та кроки, яких вона вживає, щоб їх запобігти.
- Інструментальні пояснення: Часто кажуть, що LLM у стилі ChatGPT від OpenAI є чорною скринькою, і, звичайно, в цьому є частка правди. У спробі очистити його шари, OpenAI це робить розвиваються Інструмент для автоматичного визначення частин LLM, які відповідають за їх поведінку. Інженери, які стоять за ним, підтверджують, що він знаходиться на ранніх стадіях, але код для його запуску доступний у відкритому коді на GitHub на цьому тижні.
- IBM запускає нові служби ШІ: На своїй щорічній конференції Think IBM анонсувала IBM Watsonx, нову платформу, яка надає інструменти для побудови моделей штучного інтелекту та забезпечує доступ до готових моделей для створення комп’ютерного коду, сценаріїв тощо. У компанії стверджують, що запуск був зумовлений проблемами, з якими досі стикаються багато компаній у розгортанні ШІ на робочому місці.
інше машинне навчання

Автори зображення: Падіння ШІ
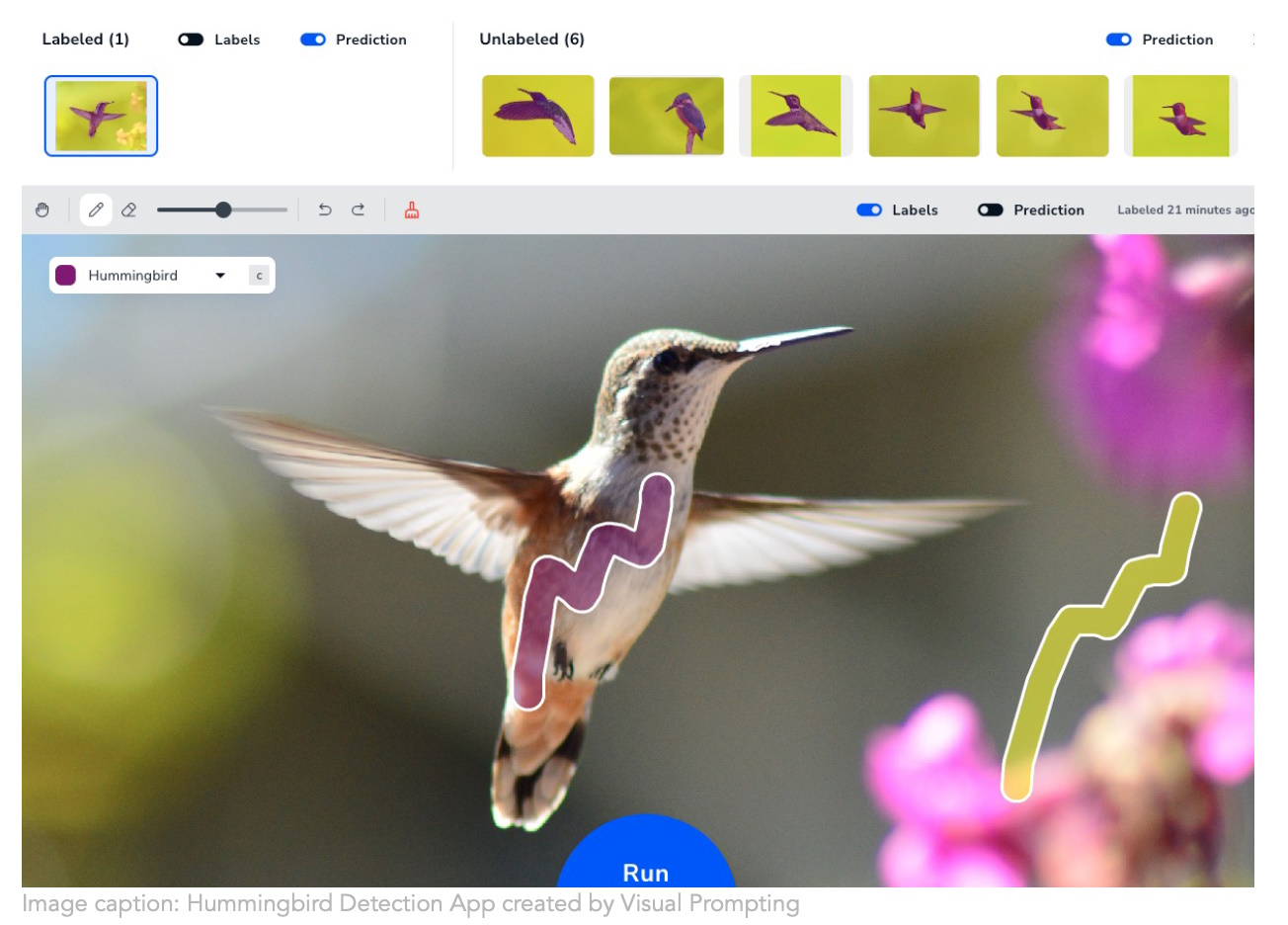
Нова компанія Andrew Ng Падіння ШІ Застосовує більш інтуїтивний підхід до створення тренувань комп’ютерного зору. Однак створення моделі, яка розуміє, що ви хочете визначити на зображеннях, дуже стомлююче Їх техніка «візуальної стимуляції» Він просто дозволяє зробити кілька мазків пензлем і звідти встановлює ваш намір. Будь-хто, кому доводиться створювати моделі сегментації, каже: «О Боже, нарешті!» Ймовірно, є багато аспірантів, які зараз годинами ховають органели та предмети побуту.
Реалізовано Microsoft Дифузійні моделі унікальним і цікавим способом, по суті, використовуючи їх для створення вектора дії замість зображення, після навчання в багатьох спостережуваних людських діях. Це все ще дуже рано, і дифузія не є очевидним вирішенням цієї проблеми, але оскільки вони настільки стабільні та універсальні, цікаво подивитися, як їх можна застосувати за межі суто візуальних завдань. Їх документ буде представлено на ICLR пізніше цього року.

Автори зображення: мета
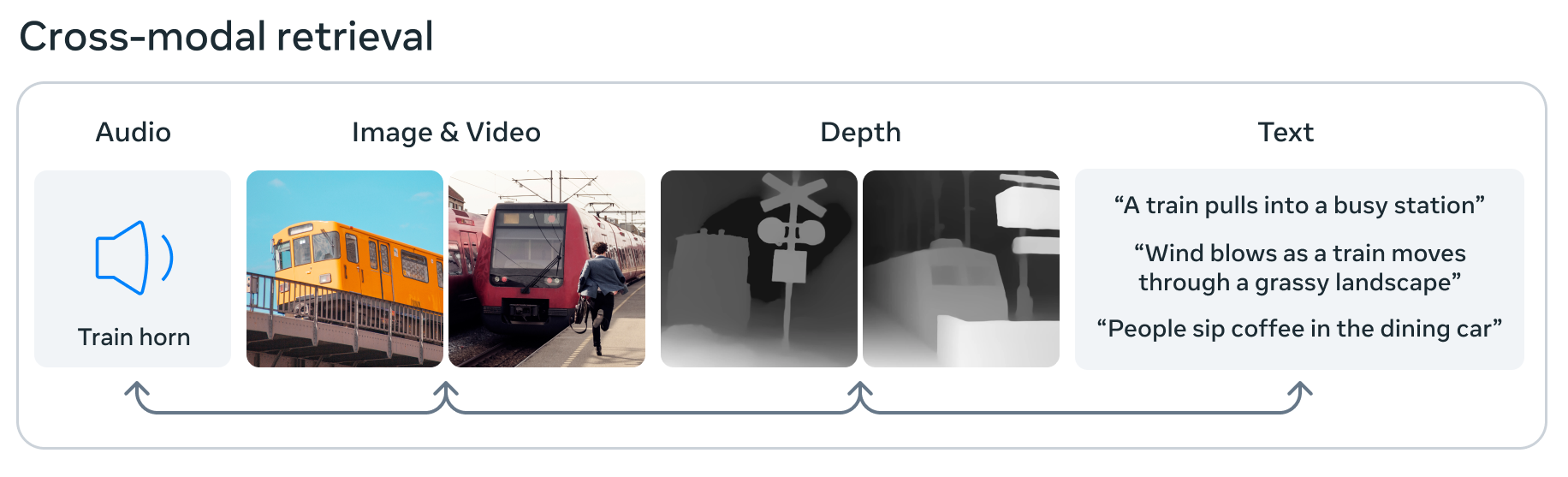
Meta також розширює можливості штучного інтелекту ImageBind, яка, як стверджується, є першою моделлю, яка може обробляти та поєднувати дані з шести різних методів: зображення, відео, аудіо, 3D-дані глибини, теплову інформацію та дані про рух або позицію. Це означає, що в невеликому просторі для вбудовування машинного навчання зображення може бути пов’язане зі звуком, тривимірною формою та різними текстовими описами, будь-яке з яких можна відняти або використати для прийняття рішення. Це крок до «загального» штучного інтелекту в тому, що він поглинає та корелює дані, як мозок, але він все ще базовий і експериментальний, тож поки не надто хвилюйтеся.

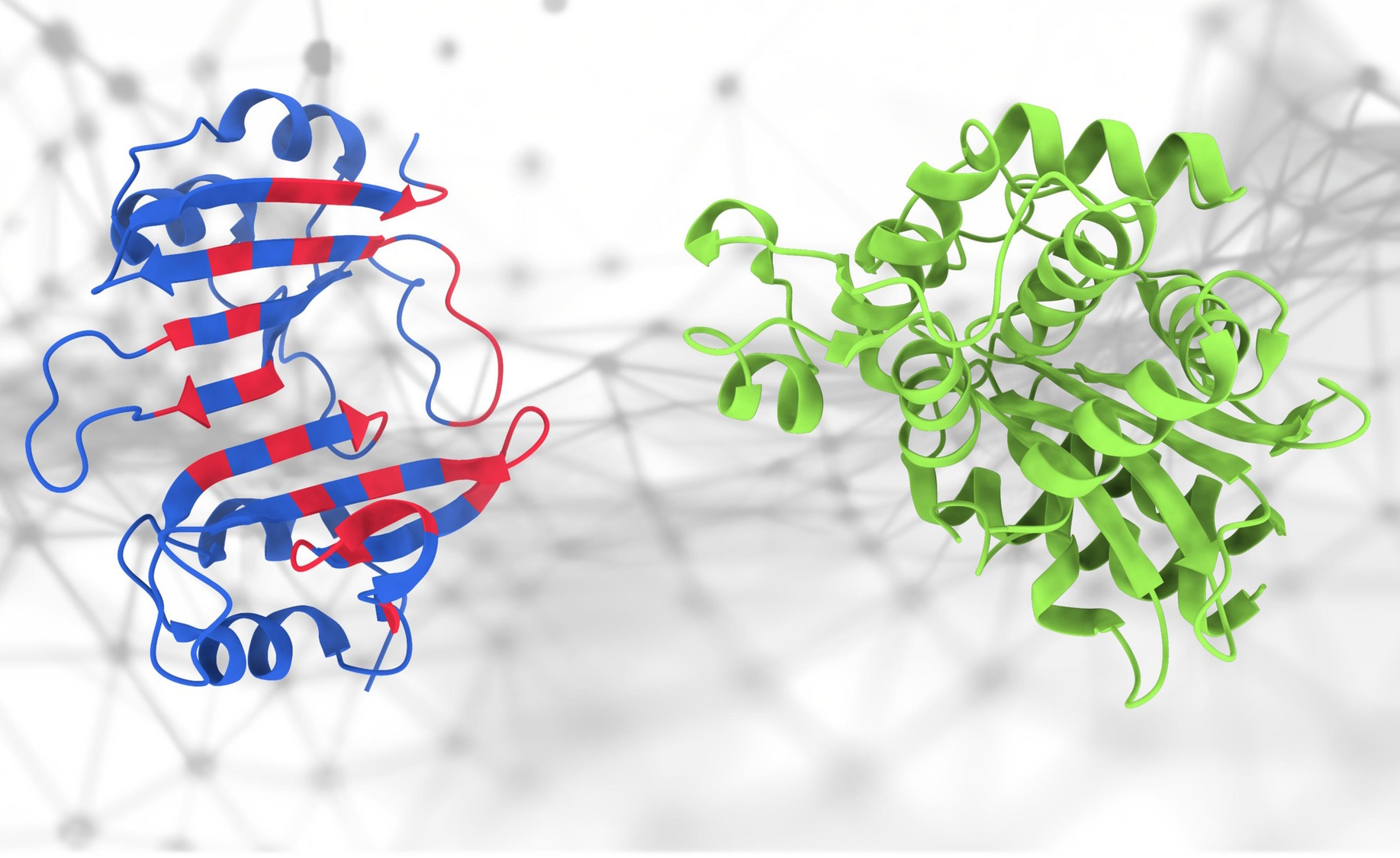
Якщо торкнутися цих білків… що станеться?
Усі були в захваті від AlphaFold, і не дарма, але ця структура насправді є лише невеликою частиною дуже складної науки про протеоміку. Те, як ці білки взаємодіють, важливо і важко передбачити, але це нове Модель PeSTo від EPFL Він намагається робити саме це. «Він зосереджений на важливих атомах і взаємодіях у структурі білка», — сказав провідний розробник Люсьєн Краббе. «Це означає, що цей метод ефективно фіксує складні взаємодії в білкових структурах, щоб забезпечити точне передбачення інтерфейсів зв’язування білка». Навіть якщо це не на 100% точно чи надійно, не потрібно починати з нуля, це дуже корисно для дослідників.
Федерали збираються ШІ. Бос навіть закинув a Знайомтеся з групою генеральних директорів штучного інтелекту Щоб показати, наскільки важливо це зробити правильно. Можливо, групі компаній не обов’язково підійде запит, але вони принаймні матимуть кілька ідей, які варто розглянути. Але вони вже мають лобістів, чи не так?
Я більше в захваті від З’являються нові дослідницькі центри штучного інтелекту, які фінансуються з федерального бюджету. Фундаментальні дослідження вкрай необхідні, щоб збалансувати роботу, зосереджену на продукті, яку виконують OpenAI і Google, тому, коли у вас є центри ШІ з повноваженнями досліджувати такі речі, як Соціальні науки (в КМУ)або зміна клімату та сільське господарство (в університеті Міннесоти), виглядає як зелені поля (в переносному і прямому значенні). Хоча я також хочу трохи привітати цю Метапошук лісової міри.


Практикувати ШІ разом на великому екрані – це ціла наука!
Багато цікавих розмов про штучний інтелект. я вірив Це інтерв’ю з академіками UCLA (моя alma mater, Go Bruins) Джейкобом Фостером і Денні Снелсоном Було дуже цікаво. Ось чудова ідея LLM, щоб удавати, що ви прийшли цими вихідними, коли люди говорять про ШІ:
Ці системи визначають узгодженість більшості письмових форм формально. Чим загальніші формати імітують ці прогностичні моделі, тим вони успішніші. Ці розробки спонукають нас дізнатися про модульні функції наших форм та їх можливу трансформацію. Після появи фотографії, яка дуже добре фіксує репрезентативний простір, у середовищі живопису розвинувся імпресіонізм, стиль, який повністю відкинув точне зображення, щоб залишитися при матеріальності самої фарби.
Однозначно використовую це!

“Загальний ніндзя в соціальних мережах. Інтроверт. Творець. Шанувальник телебачення. Підприємець, що отримує нагороди. Веб-ботанік. Сертифікований читач”




